ArXiv, 2026
PaperProject pageCodeAbstractBibtex
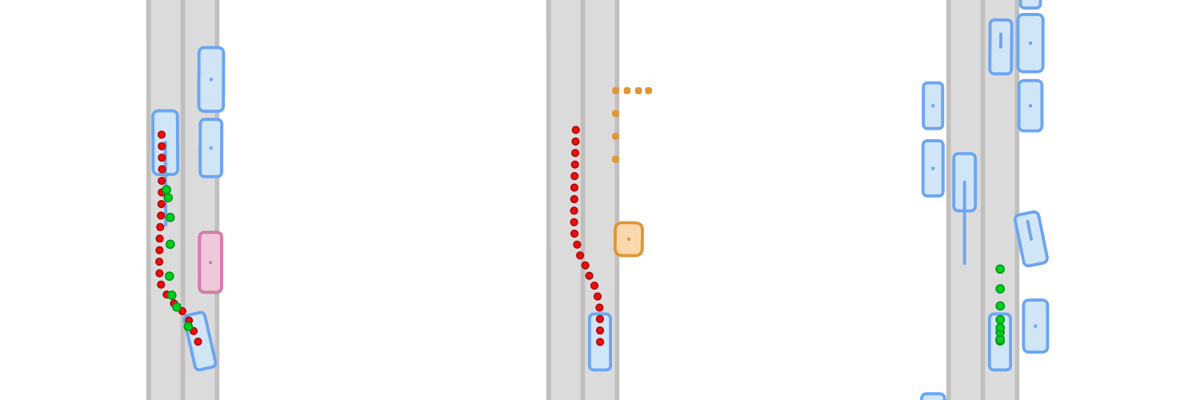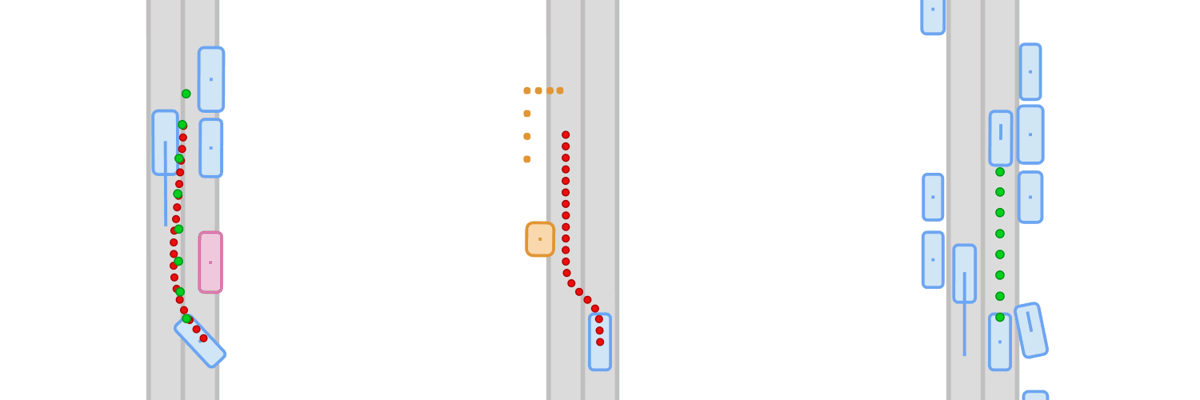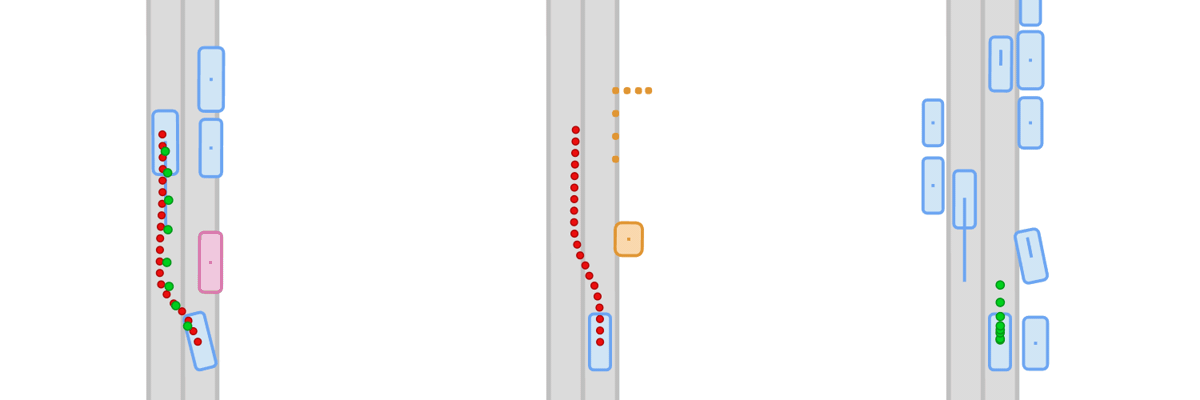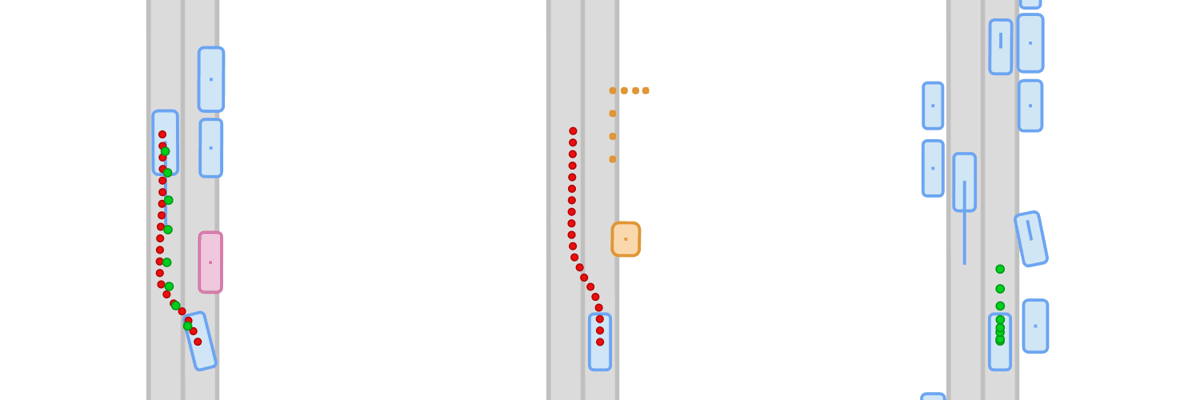
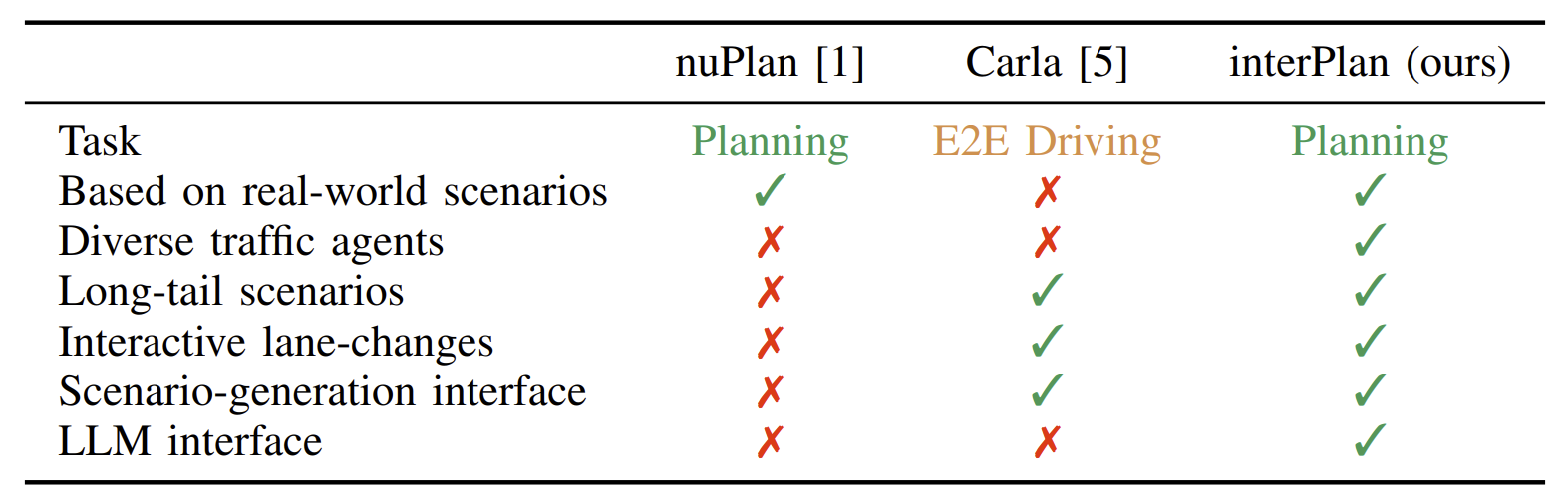
Generalization under distribution shift remains a central bottleneck for closed-loop autonomous driving. Although simulators like CARLA enable safe and scalable testing, existing benchmarks rarely measure true generalization: they typically reuse training scenarios at test time. Success can therefore reflect memorization rather than robust driving behavior. We introduce Fail2Drive, the first paired-route benchmark for closed-loop generalization in CARLA, with 200 routes and 17 new scenario classes spanning appearance, layout, behavioral, and robustness shifts. Each shifted route is matched with an in-distribution counterpart, isolating the effect of the shift and turning qualitative failures into quantitative diagnostics. Evaluating multiple state-of-the-art models reveals consistent degradation, with an average success-rate drop of 22.8%. Our analysis uncovers unexpected failure modes, such as ignoring objects clearly visible in the LiDAR and failing to learn the fundamental concepts of free and occupied space. To accelerate follow-up work, Fail2Drive includes an open-source toolbox for creating new scenarios and validating solvability via a privileged expert policy. Together, these components establish a reproducible foundation for benchmarking and improving closed-loop driving generalization. We open-source all code, data, and tools.
@article{Gerstenecker2026Fail2Drive,
author={Gerstenecker, Simon and Geiger, Andreas and Renz, Katrin},
title={Fail2Drive: Benchmarking Closed-Loop Driving Generalization},
journal={arXiv preprint arXiv:2604.08535},
year={2026}
}